Neural Network
Linear Classifiers cannot deal with non-linear boundaries.
such as two circles with different radius but the same center point.
—> use polar coordinate to create a feature space. is the x axis and the is the y axis.
all points on the same circle is seated on the same vertical line that is parallel to the y axis.
(Before) Linear score function: only a small part of Feature Extraction can adjust itself to better maximizing its ability.
Learn only one template of one category.
(After) Neural Network: raw picture pixel —> classification scores
Learn several templates of one category.
Linear score function:
2-layer Neural Network:
Element of gives the effect on from
Deep Neural Networks: Depth = number of layers = number of Matrix
Width = Size of each layer
Activation Functions:
Without the activation function,we will go back to which is linear classifiers.
| Activation Functions | Expression | Graph |
|---|---|---|
| Sigmoid | 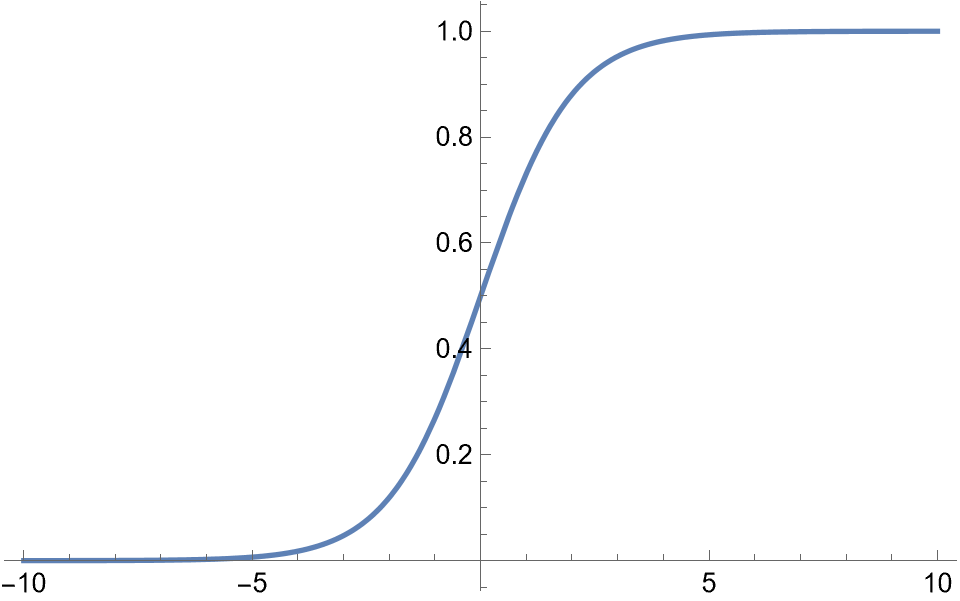 | |
| tanh | tanh(x) | 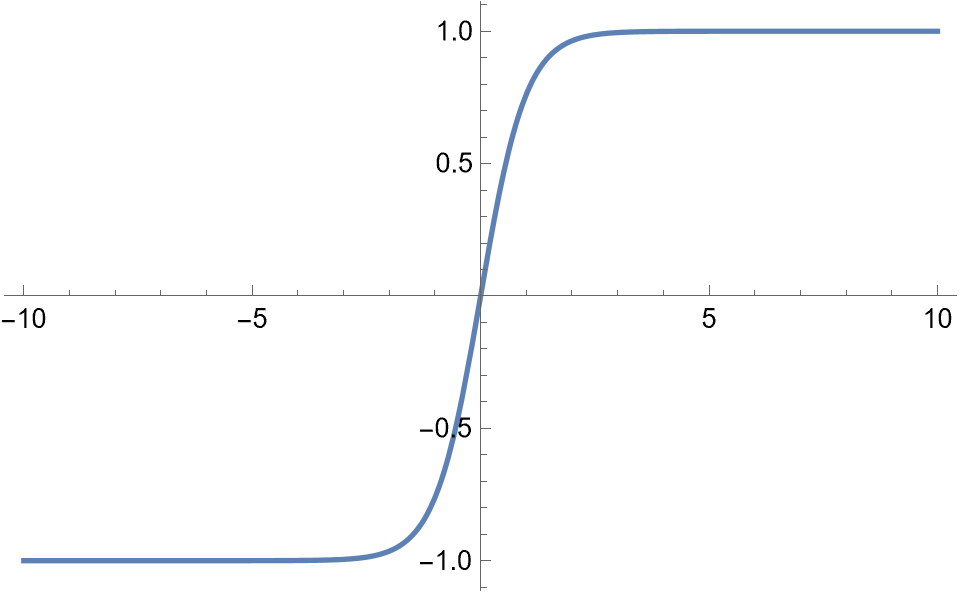 |
| ReLU(A good default choice for most problems) | max(0,x) | 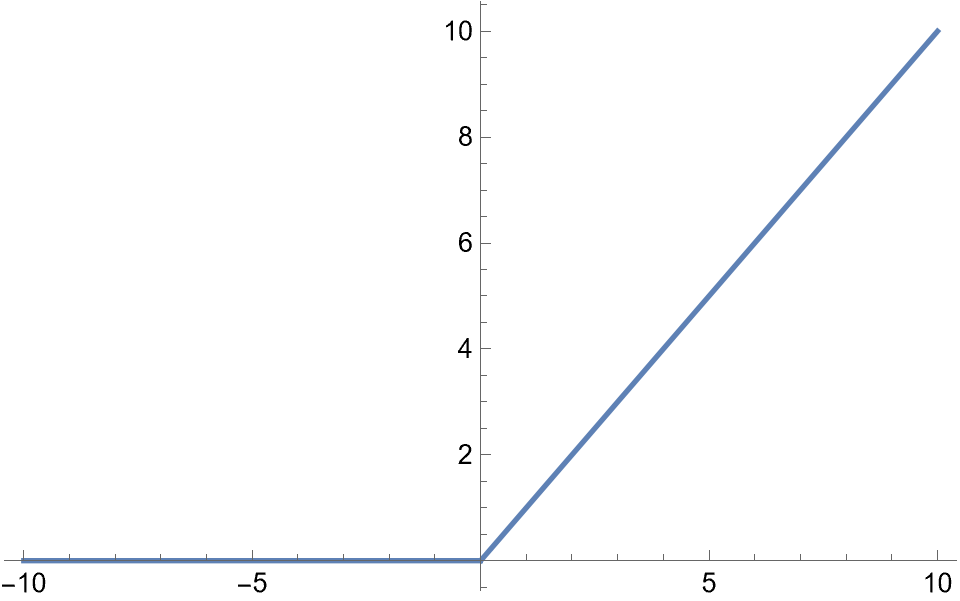 |
A simple achievement:
import numpy as np
from numpy.random import randn
N,Din,H,Dout = 64,1000,100,10
x,y = randn(N,Din),randn(N,Dout)
w1,w2 = randn(Din,H),randn(H,Dout)
for t in range(10000):
h = 1.0 / (1.0 + np.exp(-x.dot(w1)))
y_pred = h.dot(w2)
loss = np.square(y_pred - y).sum()
dy_pred = 2.0 * (y_pred - y)
dw2 = h.T.dot(dy_pred)
dh = dy_pred.dot(w2.T)
dw1 = x.T.dot(dh*h*(1-h))
w1 -= 1e-4 * dw1
w2 -= 1e-4 * dw2Space warping:
Linear transform cannot linearly separate points even in feature space.
but with ReLU function,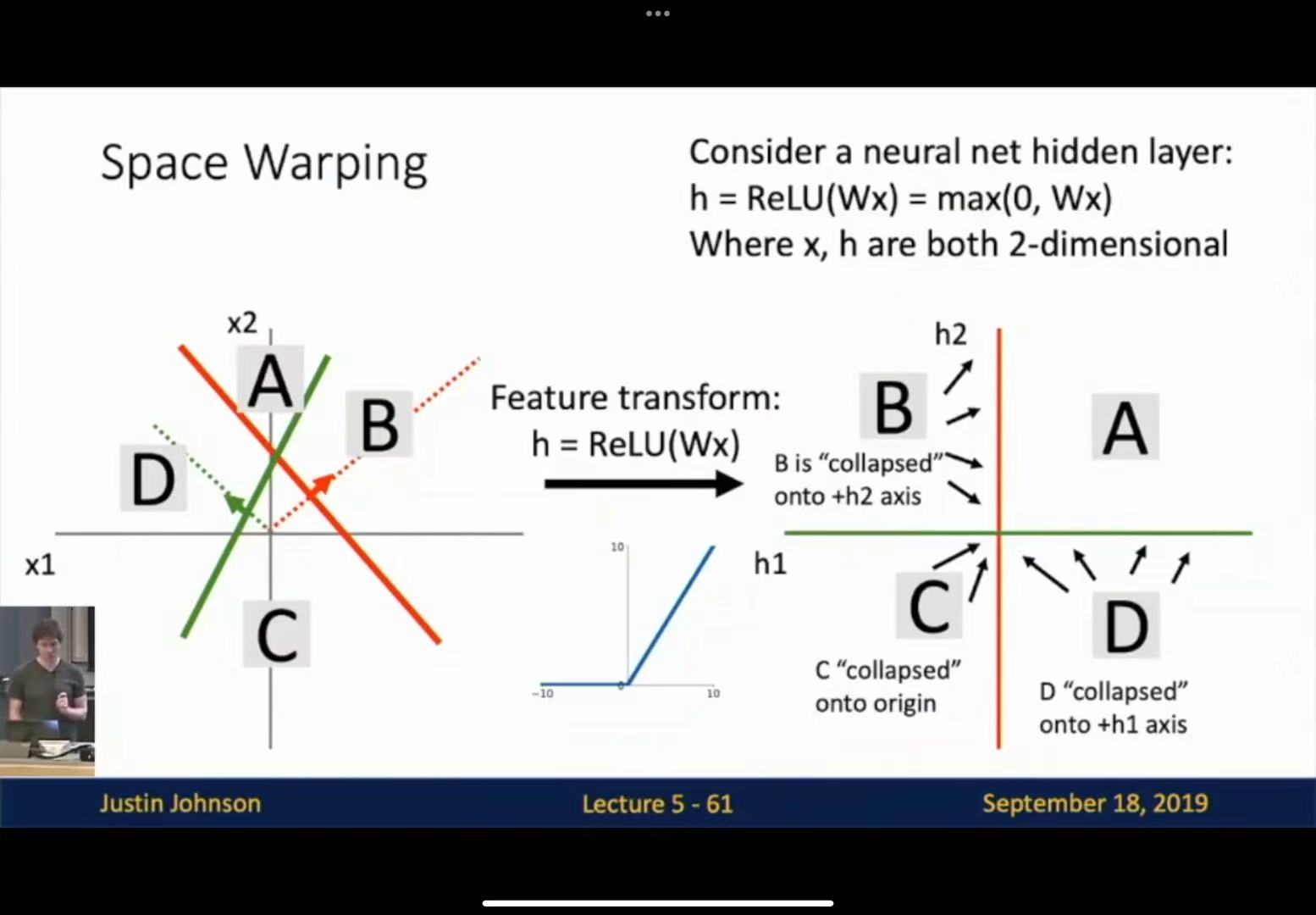
Universal Approximation:
use layer bias to move the graph
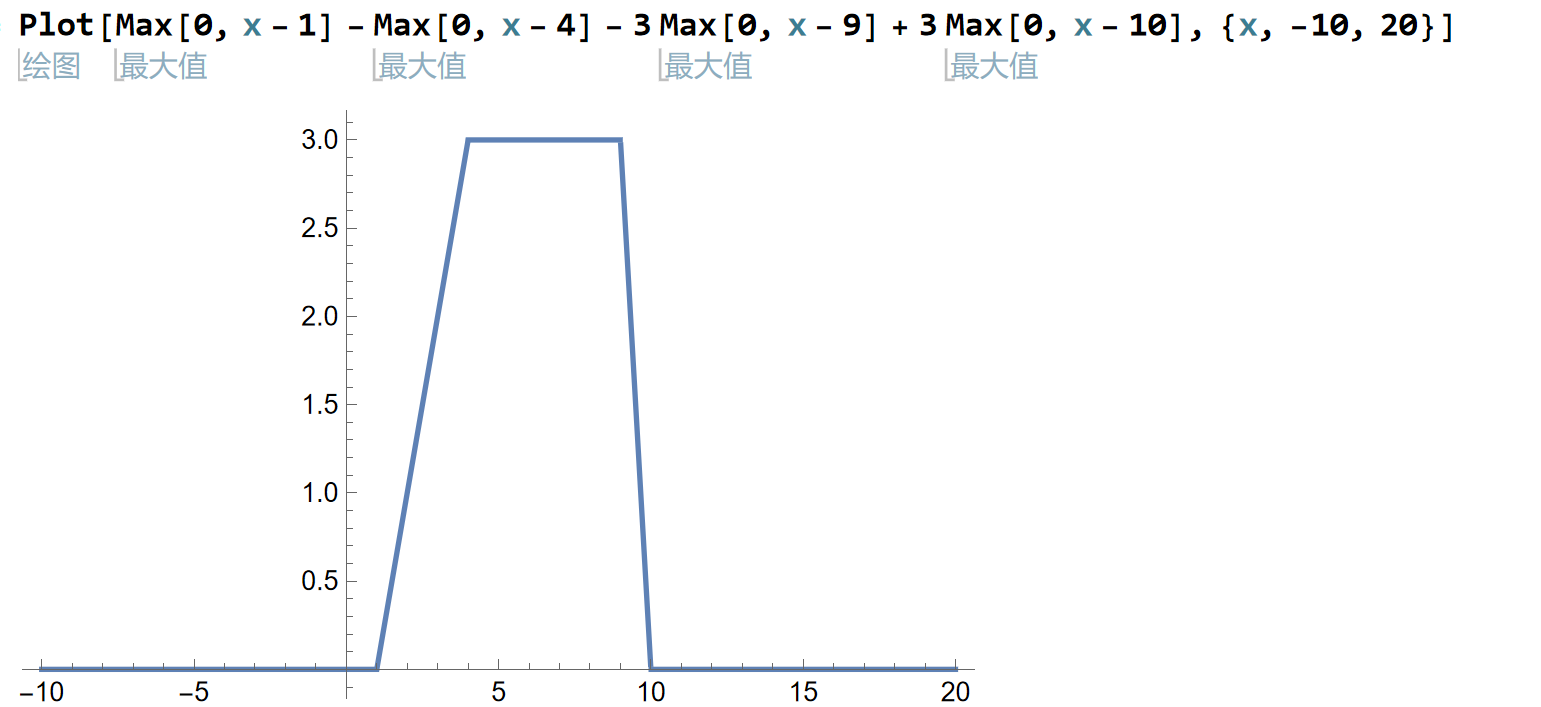
use many ReLU to approach the function.
to reach 0 or unchanged: slope should be opposite
let coefficient of x be 1,only change the shaping factor of MAX.
Convex Functions:
is convex if for all
convex is easy to optimize